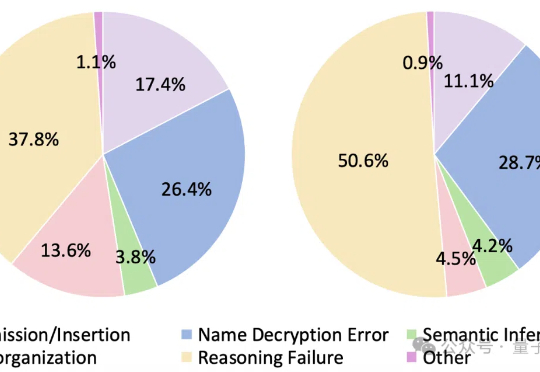
SOTA大模型遇上加密数据评测:Qwen3未破10%,o1也栽了丨上海AI Lab等联合研究
SOTA大模型遇上加密数据评测:Qwen3未破10%,o1也栽了丨上海AI Lab等联合研究大语言模型遇上加密数据,即使是最新Qwen3也直冒冷汗!
来自主题: AI技术研报
8909 点击 2025-05-29 14:59
 搜索
搜索
大语言模型遇上加密数据,即使是最新Qwen3也直冒冷汗!

2002年,在拿下中国高校第一个ACM(计算机领域最顶尖的程序设计大赛)金牌后,上海交大设立了“ACM班”,这个用最高竞赛命名的班级后来人尽皆知,成为中国AI人才的重要阵地。也在那年,李磊成为ACM班第一届的学生。在ACM班他第一次意识到,“原来计算机能帮助解决人类的这么多问题。”
围棋因其独特的复杂性和对人类智能的深刻体现,可作为衡量AI专业能力最具代表性的任务之一。
OpenAI 研究员姚顺雨近期发布文章,指出:AI 下半场将聚焦问题定义与评估体系重构。在 AI 发展新阶段,行业需要通过设计更有效的模型评测体系,弥补 AI 能力与真实需求的差距。

来自香港科技大学、腾讯西雅图AI Lab、爱丁堡大学、Miniml.AI、英伟达的研究者联合提出了MMLongBench,旨在全面评估多模态模型的长文本理解能力。

4月29日,腾讯TEG进行架构调整,新成立大语言和多模态模型部,并对数据平台和机器学习平台职责进行调整。
长文本能力对语言模型(LM,Language Model)尤为重要,试想,如果 LM 可以处理无限长度的输入文本,我们可以预先把所有参考资料都喂给 LM,或许 LM 在应对人类的提问时就会变得无所不能。

继吴永辉担任字节 AI 研发部门 Seed 的负责人后,Seed 组织正在陆续调整。
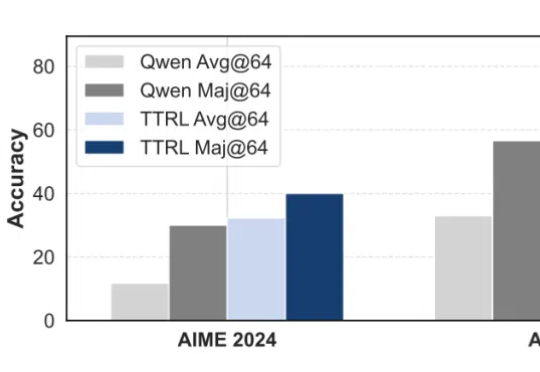
无需数据标注,在测试时做强化学习,模型数学能力暴增159%!

现在下场做 AI 产品的创业者越来越多,但创业总归是“九死一生”的艰难旅途,我更关心的是,有没有一些有迹可循的办法,能提高成功率?上周,我和一位非典型 AI 创业者——米可世界 AI Lab 的负责人 Simon 聊了一次天,聊出了很多在 AI 创业的宏大叙事中没有的“大实话”,也获得了不少启发。